Comparing Sentiment Labeling with RoBERTa and IndoBERTweet on Public Opinion of Program Makan Bergizi Gratis
DOI:
https://doi.org/10.56705/ijodas.v7i1.381Keywords:
Makan Bergizi Gratis (MBG) Program, IndoBERTweet, Public Opinion, RoBERTa, Sentiment Analysis, TransformerAbstract
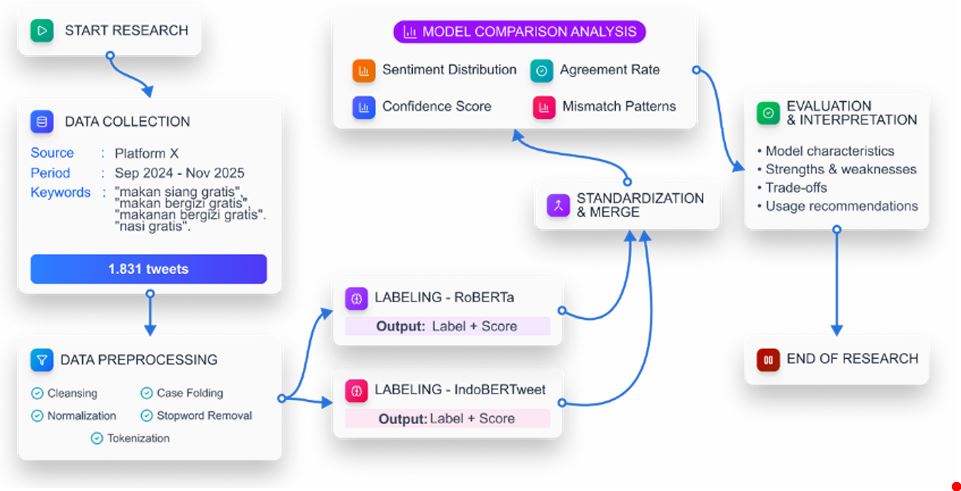
The Program Makan Bergizi Gratis (MBG) is a flagship program of the Prabowo Subianto administration launched in 2024, triggering diverse public responses on social media. Sentiment analysis using deep learning models offers an effective approach to understanding public opinion at scale. However, selecting the appropriate model for Indonesian social media text remains challenging. This study aims to compare the performance of two pretrained transformer models, RoBERTa Base and IndoBERTweet Base, in conducting automatic sentiment labeling on Indonesian tweets related to the MBG program using a zero-shot labeling approach without human-annotated ground truth. A total of 1,831 tweets were collected from platform X and preprocessed using case folding, normalization, and stopword removal. Both models were applied in parallel to label each tweet with sentiment categories (positive, neutral, negative) along with confidence scores. The comparison was evaluated using agreement rate, Cohen's Kappa, and confidence score analysis. RoBERTa Base exhibits a conservative tendency with 75.20% neutral labels, while IndoBERTweet Base produces a more balanced distribution (68.16% neutral). The comparison shows 77.28% agreement with Cohen's Kappa of 0.490 (Moderate Agreement). RoBERTa Base achieves higher confidence (mean: 0.9559, 83.01% above 0.95) compared to IndoBERTweet Base (mean: 0.9236, 68.65% above 0.95). IndoBERTweet Base is more effective in detecting negative sentiment, identifying nearly twice as many negative tweets (13.54% vs. 7.48%). This study recommends IndoBERTweet Base for exploratory research requiring sensitive sentiment detection and RoBERTa Base for precision-critical applications. An ensemble approach combining both models is recommended for production-critical applications
Downloads
References
[1] A. A. Saleh, S. Abdullah, R. Muhammad, M. Y. Amir, and S. Sulvinajayanti, “Rethinking School Nutrition via Community Engagement: A Review with Implications for Indonesia’s MBG Program,” Media Kesehat. Masy. Indones., vol. 21, no. 3, pp. 259–273, Sep. 2025, doi: 10.30597/mkmi.v21i3.46204.
[2] A. Koswara and L. Herlina, “A Collaborative Model for Funding Indonesiaâ€TMs MBG Program Through Government and Philanthropy Partnerships,” J. Islam. Econ. Philanthr., vol. 7, no. 4, pp. 266–288, 2025, doi: 10.21111/jiep.v7i4.13960.
[3] E. Wildanu and H. Nauli Fitri Agasya, “Presidential Election Campaign of the Republic of Indonesia via Twitter (X),” J. Polisci, vol. 1, no. 3, pp. 132–141, 2024, doi: 10.62885/polisci.v1i3.159.
[4] E. Haddi, X. Liu, and Y. Shi, “The Role of Text Pre-processing in Sentiment Analysis,” Procedia Comput. Sci., vol. 17, pp. 26–32, 2013, doi: 10.1016/j.procs.2013.05.005.
[5] W. Medhat, A. Hassan, and H. Korashy, “Sentiment analysis algorithms and applications : A survey,” Ain Shams Eng. J., vol. 5, no. 4, pp. 1093–1113, 2014, doi: 10.1016/j.asej.2014.04.011.
[6] K. Hilary, K. Fitri, I. Anindaputri, P. Aziza, F. Aji, and I. Anindaputri, “ScienceDirect Performance Performance comparison comparison of of deep deep learning learning approaches approaches for for Indonesian twitter hate speech detection using IndoBERTweet Indonesian twitter hate speech detection using IndoBERTweet embedding e,” Procedia Comput. Sci., vol. 269, pp. 1663–1671, 2025, doi: 10.1016/j.procs.2025.09.109.
[7] N. A. Semary, W. Ahmed, K. Amin, P. Pławiak, and M. Hammad, “Improving sentiment classification using a RoBERTa-based hybrid model,” Front. Hum. Neurosci., vol. 17, no. December, pp. 1–10, 2023, doi: 10.3389/fnhum.2023.1292010.
[8] Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” no. 1, Jul. 2019, doi: 10.48550/arXiv.1907.11692.
[9] F. Koto, J. H. Lau, and T. Baldwin, “IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effective Domain-Specific Vocabulary Initialization,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M.-F. Moens, X. Huang, L. Specia, and S. W. Yih, Eds., Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 10660–10668. doi: 10.18653/v1/2021.emnlp-main.833.
[10] H. Jayadianti, W. Kaswidjanti, A. T. Utomo, S. Saifullah, F. A. Dwiyanto, and R. Drezewski, “Sentiment analysis of Indonesian reviews using fine-tuning IndoBERT and R-CNN,” Ilk. J. Ilm., vol. 14, no. 3, pp. 348–354, Dec. 2022, doi: 10.33096/ilkom.v14i3.1505.348-354.
[11] R. Mukarramah, D. Atmajaya, and L. B. Ilmawan, “Performance comparison of support vector machine (SVM) with linear kernel and polynomial kernel for multiclass sentiment analysis on twitter,” Ilk. J. Ilm., vol. 13, no. 2, pp. 168–174, 2021, doi: 10.33096/ilkom.v13i2.851.168-174.
[12] D. Indra, R. Ramdaniah, and W. Sukur, “Analysis of Hybrid Learning Sentiment among Information Systems Students using The Naïve Bayes Classifier,” J. ELTIKOM, vol. 8, no. 2, pp. 91–99, Dec. 2024, doi: 10.31961/eltikom.v8i2.1144.
[13] F. Koto, A. Rahimi, J. H. Lau, and T. Baldwin, “IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP,” in COLING 2020 - 28th International Conference on Computational Linguistics, Proceedings of the Conference, 2020, pp. 757–770. doi: 10.18653/v1/2020.coling-main.66.
[14] M. R. Setyawan, ; Fajar, R. B. Putra, and A. Ramadhani, “Sentiment Analysis towards Jokowi Post-Presidential Term Using CNN-BiLSTM with Multi-head Attention on Platform X,” Ilk. J. Ilm., vol. 17, no. 2, pp. 150–161, 2025, doi: 10.33096/ilkom.v17i2.2843.150-161.
[15] H. R. P. Sianturi, “Politics on a plate: equivocal communication in Indonesian presidential nutrition policy,” Front. Commun., vol. 10, no. September 2025, pp. 1–7, 2025, doi: 10.3389/fcomm.2025.1612652.
[16] M. K. Anam, T. A. Fitri, A. Agustin, L. Lusiana, M. B. Firdaus, and A. T. Nurhuda, “Sentiment Analysis for Online Learning using The Lexicon-Based Method and The Support Vector Machine Algorithm,” Ilk. J. Ilm., vol. 15, no. 2, pp. 290–302, 2023, doi: 10.33096/ilkom.v15i2.1590.290-302.
[17] Hengky Triyo, Aji Primajaya, and Purwantoro, “Public Sentiment Analysis on the Increase of Value Added Tax in Indonesia Through Tweet-Harvest,” J. Artif. Intell. Eng. Appl., vol. 5, no. 1, pp. 1996–2000, Oct. 2025, doi: 10.59934/jaiea.v5i1.1772.
[18] R. Rahmaddeni, M. K. Anam, Y. Irawan, S. Susanti, and M. Jamaris, “Comparison of Support Vector Machine and XGBSVM in Analyzing Public Opinion on Covid-19 Vaccination,” Ilk. J. Ilm., vol. 14, no. 1, pp. 32–38, 2022, doi: 10.33096/ilkom.v14i1.1090.32-38.
[19] T. A. Putra, V. Ariandi, and S. Defit, “Enhancing Accuracy by Using Boosting and Stacking Techniques on the Random Forest Algorithm on Data from Social Media X,” Ilk. J. Ilm., vol. 16, no. 2, pp. 184–189, 2024, doi: 10.33096/ilkom.v16i2.2058.184-189.
[20] S. Suswadi and M. Erkamim, “Sentiment Analysis of Shopee App Reviews Using Random Forest and Support Vector Machine,” Ilk. J. Ilm., vol. 15, no. 3, pp. 427–435, 2023, doi: 10.33096/ilkom.v15i3.1610.427-435.
[21] I. Irawanto, C. Widodo, A. Hasanah, P. A. Dharma Kusumah, K. Kusrini, and K. Kusnawi, “Sentiment Analysis and Classification of Forest Fires in Indonesia,” Ilk. J. Ilm., vol. 15, no. 1, pp. 175–185, 2023, doi: 10.33096/ilkom.v15i1.1337.175-185.
[22] L. B. Ilmawan, M. Muladi, and D. D. Prasetya, “Feature Space Augmentation for Negation Handling on Sentiment Analysis,” Ilk. J. Ilm., vol. 15, no. 2, pp. 353–357, 2023, doi: 10.33096/ilkom.v15i2.1695.353-357.
[23] M. A. Rosid, A. S. Fitrani, I. R. I. Astutik, N. I. Mulloh, and H. A. Gozali, “Improving Text Preprocessing for Student Complaint Document Classification Using Sastrawi,” IOP Conf. Ser. Mater. Sci. Eng., vol. 874, no. 1, 2020, doi: 10.1088/1757-899X/874/1/012017.
[24] I. As’ad, M. A. Asis, H. M. Pakka, R. Mursalim, and Y. binti M. Noor, “K-Nearest Neighbors Analysis for Public Sentiment towards Implementation of Booster Vaccines in Indonesia,” Ilk. J. Ilm., vol. 15, no. 2, pp. 365–372, 2023, doi: 10.33096/ilkom.v15i2.1561.365-372.
[25] E. Yulianti and N. K. Nissa, “ABSA of Indonesian customer reviews using IndoBERT: single-sentence and sentence-pair classification approaches,” Bull. Electr. Eng. Informatics, vol. 13, no. 5, pp. 3579–3589, 2024, doi: 10.11591/eei.v13i5.8032.
[26] T. Wolf et al., “Transformers: State-of-the-Art Natural Language Processing,” in EMNLP 2020 - Conference on Empirical Methods in Natural Language Processing, Proceedings of Systems Demonstrations, Stroudsburg, PA, USA: Association for Computational Linguistics, 2020, pp. 38–45. doi: 10.18653/v1/2020.emnlp-demos.6.
[27] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” NAACL HLT 2019 - 2019 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. - Proc. Conf., vol. 1, no. Mlm, pp. 4171–4186, May 2019, doi: 10.48550/arXiv.1810.04805.
[28] E. P. A. Akhmad, “Sentiment Analysis of DLU Ferry Application Reviews on the Google Play Store Using Bidirectional Encoder Representations from Transformers,” J. Apl. PELAYARAN DAN KEPELABUHANAN, vol. 13, no. 2 SE-Articles, pp. 104–112, Mar. 2023, doi: 10.30649/japk.v13i2.94.
[29] J. Grabinski, P. Gavrikov, J. Keuper, and M. Keuper, “Robust Models are less Over-Confident,” Adv. Neural Inf. Process. Syst., vol. 35, no. NeurIPS, Dec. 2022, doi: 10.48550/arXiv.2210.05938.
[30] D. Contreras, S. Wilkinson, E. Alterman, and J. Hervás, “Accuracy of a pre-trained sentiment analysis (SA) classification model on tweets related to emergency response and early recovery assessment: the case of 2019 Albanian earthquake,” Nat. Hazards, vol. 113, no. 1, pp. 403–421, 2022, doi: 10.1007/s11069-022-05307-w.
[31] M. L. McHugh, “Interrater reliability: the kappa statistic,” Biochem. Medica, vol. 22, no. 3, pp. 276–282, 2012, doi: 10.11613/BM.2012.031.
[32] M. Albrektsson, O. Wolf, A. Enocson, and M. Sundfeldt, “Validation of the classification of surgically treated acetabular fractures in the Swedish Fracture Register,” Injury, vol. 53, no. 6, pp. 2145–2149, 2022, doi: 10.1016/j.injury.2022.03.002.
[33] A. Michael and M. Garonga, “Classification model of ‘Toraja’ arabica coffee fruit ripeness levels using convolution neural network approach,” Ilk. J. Ilm., vol. 13, no. 3, pp. 226–234, 2021, doi: 10.33096/ilkom.v13i3.861.226-234.
[34] S. Wu and M. Dredze, “Are All Languages Created Equal in Multilingual BERT?,” in Proceedings of the 5th Workshop on Representation Learning for NLP, S. Gella, J. Welbl, M. Rei, F. Petroni, P. Lewis, E. Strubell, M. Seo, and H. Hajishirzi, Eds., Stroudsburg, PA, USA: Association for Computational Linguistics, Jul. 2020, pp. 120–130. doi: 10.18653/v1/2020.repl4nlp-1.16.
[35] R. Joshi, “L3Cube-MahaCorpus and MahaBERT: Marathi Monolingual Corpus, Marathi BERT Language Models, and Resources,” 6th Work. Indian Lang. Data Resour. Eval. WILDRE 2022 - held conjunction with Int. Conf. Lang. Resour. Eval. Lr. 2022 - Proc., no. June, pp. 97–101, Mar. 2022.
[36] F. Z. Lubis and R. Kurniawan, “Sentiment analysis towards naturalization of Indonesian National Team Players on social media x using the Naive Bayes method,” J. Mandiri IT, vol. 14, no. 1, pp. 208–218, 2025, doi: 10.35335/mandiri.v14i1.412.
[37] N. K. Ode, D. Indra, and R. Ramdaniah, “Sentiment Analysis of Public Opinion on Deforestation in Papua on YouTube Platform Using Long Short-Term Memory (LSTM) Method,” G-Tech J. Teknol. Terap., vol. 9, no. 4, pp. 1878–1888, Oct. 2025, doi: 10.70609/g-tech.v9i4.7855.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Putri Nur Rezky, Dolly Indra, Herdianti

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Authors retain copyright and full publishing rights to their articles. Upon acceptance, authors grant Indonesian Journal of Data and Science a non-exclusive license to publish the work and to identify itself as the original publisher.
Self-archiving. Authors may deposit the submitted version, accepted manuscript, and version of record in institutional or subject repositories, with citation to the published article and a link to the version of record on the journal website.
Commercial permissions. Uses intended for commercial advantage or monetary compensation are not permitted under CC BY-NC 4.0. For permissions, contact the editorial office at ijodas.journal@gmail.com.
Legacy notice. Some earlier PDFs may display “Copyright © [Journal Name]” or only a CC BY-NC logo without the full license text. To ensure clarity, the authors maintain copyright, and all articles are distributed under CC BY-NC 4.0. Where any discrepancy exists, this policy and the article landing-page license statement prevail.












