Comparative Analysis of OCR Methods Integrated with Fuzzy Matching for Food Ingredient Detection in Japanese Packaged Products
DOI:
https://doi.org/10.56705/ijodas.v6i2.257Keywords:
Allergen Detection, Google Vision OCR, Paddle OCR, Tesseract OCR, Fuzzy MatchingAbstract
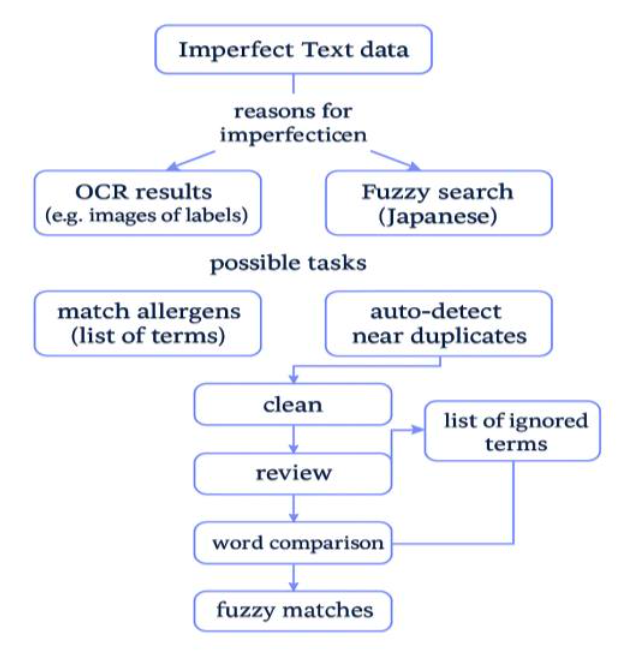
Advances in digital technology offer a solution to the challenges faced by foreign consumers in understanding ingredient information on Japanese food packaging, especially due to the use of Kanji, Hiragana, and Katakana characters. This study develops and reveals an allergen detection method based on Optical Character Recognition (OCR) and fuzzy match applied to Japanese food packaging. Three OCR methods—Google Vision OCR, PaddleOCR, and Tesseract OCR—were compared and evaluated using Precision, Recall, F1-Score, and Confusion Matrix metrics.The study began with the collection of food product images from bold sources, followed by text extraction using the three OCR methods. The extracted text was then cleaned and normalized before being matched with ground truth data using fuzzy match. Testing was conducted on 10 product image samples with varying quality and lighting conditions. The results showed that Google Vision OCR outperformed the others, achieving an average F1 score of 1.00, followed by PaddleOCR (0.75), and Tesseract OCR (0.30). Google Vision was the most consistent in detecting allergens such as 乳 (milk), 小麦 (wheat), and 卵 (egg). These findings suggest that the integration of OCR and fuzzy matching is effective in detecting allergens, even in the presence of textual variations and recognition errors. This study contributes to the development of automated food recommendation systems for foreign consumers, especially those who have food preferences due to allergies, religious beliefs, or personal preferences.
Downloads
References
K. Sasaki, “Diversity of Japanese consumers’ requirements, sensory perceptions, and eating preferences for meat,” Anim. Sci. J., vol. 93, no. 1, Jan. 2022, doi: 10.1111/ASJ.13705.
K. Toratani, Ed., “The Language of Food in Japanese,” Converging Evid. Lang. Commun. Res., vol. 25, Jan. 2022, doi: 10.1075/CELCR.25.
V. Grinkov, G. Grinkova, and S. Grinkov, “V. Hrinkov, G. Hrinkova, S. Hrinkov. Analysis of modern optical character recognition tools for character recognition and text from the image,” Sist. ì Tehnol. zv’âzku, ìnformatizacìï ta kìberbezpeki, vol. 1, no. 6, pp. 75–84, Dec. 2024, doi: 10.58254/VITI.6.2024.05.75.
S. Kavin and C. P. Shirley, “OCR-Based Extraction of Expiry Dates and Batch Numbers in Medicine Packaging for Error-Free Data Entry,” Proc. Int. Conf. Circuit Power Comput. Technol. ICCPCT 2024, vol. 4, pp. 278–283, Aug. 2024, doi: 10.1109/ICCPCT61902.2024.10673325.
J. Kalluru, “Enhancing Data Accuracy and Efficiency: An Overview of Fuzzy Matching Techniques,” Int. J. Sci. Res., vol. 12, no. 8, pp. 685–690, Aug. 2023, doi: 10.21275/SR23805184140.
S. Kayalvizhi, N. Akash Silas, R. K. Tarunaa, and S. Pothirajan, “OCR-Based Ingredient Recognition for Consumer Well-Being,” Lect. Notes Networks Syst., vol. 796, pp. 481–491, Jan. 2024, doi: 10.1007/978-981-99-6906-7_41.
K. Riehl, M. Neunteufel, and M. Hemberg, “Hierarchical confusion matrix for classification performance evaluation,” Jun. 2023, doi: 10.1093/jrsssc/qlad057.
C. K. FÆste, H. T. Rønning, U. Christians, and P. E. Granum, “Liquid chromatography and mass spectrometry in food allergen detection.,” J. Food Prot., vol. 74, no. 2, pp. 316–345, Feb. 2011, doi: 10.4315/0362-028X.JFP-10-336.
C. Thorat, A. Bhat, P. Sawant, I. Bartakke, and S. Shirsath, “A Detailed Review on Text Extraction Using Optical Character Recognition,” Lect. Notes Networks Syst., vol. 314, pp. 719–728, Jan. 2022, doi: 10.1007/978-981-16-5655-2_69.
“(20+) Facebook.” Accessed: Apr. 14, 2025. [Online]. Available: https://www.facebook.com/HalalJapanOfficial/
“【楽天市場】Shopping is Entertainment! : インターネット最大級の通信販売、通販オンラインショッピングコミュニティ.” Accessed: Apr. 14, 2025. [Online]. Available: https://www.rakuten.co.jp/
J. R. Fonseca Cacho and K. Taghva, “Aligning Ground Truth Text with OCR Degraded Text,” Adv. Intell. Syst. Comput., vol. 997, pp. 815–833, Jul. 2019, doi: 10.1007/978-3-030-22871-2_58.
J. Ghorpade-Aher, S. Gajbhar, A. Sarode, G. Gayake, and P. Daund, “Text Retrieval from Natural and Scanned Images,” Int. J. Comput. Appl., vol. 133, no. 8, pp. 10–12, Jan. 2016, doi: 10.5120/IJCA2016907840.
N. P. T. Prakisya, B. T. Kusmanto, and P. Hatta, “Comparative Analysis of Google Vision OCR with Tesseract on Newspaper Text Recognition,” Media Comput. Sci., vol. 1, no. 1, pp. 31–46, Jul. 2024, doi: 10.69616/MCS.V1I1.178.
O. Krasynskyi and O. Markovets, “Possibilities of Using OCR Technologies from Google for Recognition and Digitalization of Archive Documents,” Vìsnik Harkìvsʹkoï deržavnoï Akad. kulʹturi, no. 65, pp. 227–237, Jun. 2024, doi: 10.31516/2410-5333.065.16.
“PaddlePaddle-Parallel Distributed Deep Learning, efficient and extensible deep learning framework.” Accessed: Apr. 14, 2025.
P. Sharma, “Advancements in OCR: A Deep Learning Algorithm for Enhanced Text Recognition,” Int. J. Inven. Eng. Sci., vol. 10, no. 8, pp. 1–7, Aug. 2023, doi: 10.35940/IJIES.F4263.0810823.
U. K. V. Karanth, A. T. Sujan, T. Y. R. Kumar, S. S. Joshi, A. K. P. Rani, and S. Gowrishankar, “Breaking Barriers in Text Analysis: Leveraging Lightweight OCR and Innovative Technologies for Efficient Text Analysis,” 2nd Int. Conf. Autom. Comput. Renew. Syst. ICACRS 2023 - Proc., pp. 359–366, Dec. 2023, doi: 10.1109/ICACRS58579.2023.10404305.
“GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository).” Accessed: Apr. 14, 2025. [Online]. Available: https://github.com/tesseract-ocr/tesseract
M. M. Rahman and M. R. Rinty, “Text Information Extraction from Digital Image Documents Using Optical Character Recognition,” Comput. Intell. Image Video Process., pp. 1–31, Jan. 2023, doi: 10.1201/9781003218111-1.
V. E. Bugayong, J. Flores Villaverde, and N. B. Linsangan, “Google Tesseract: Optical Character Recognition (OCR) on HDD / SSD Labels Using Machine Vision,” 2022 14th Int. Conf. Comput. Autom. Eng. ICCAE 2022, pp. 56–60, Mar. 2022, doi: 10.1109/ICCAE55086.2022.9762440.
M. K. Audichya, “A Study to Recognize Printed Gujarati Characters Using Tesseract OCR,” Int. J. Res. Appl. Sci. Eng. Technol., vol. V, no. IX, pp. 1505–1510, Sep. 2017, doi: 10.22214/IJRASET.2017.9219.
Thangam, U. Kumaran, D. Biswas, B. Sneha, S. Nadipalli, and S. Raja, “Text Post-processing on Optical Character Recognition output using Natural Language Processing Methods,” 2023 IEEE 3rd Mysore Sub Sect. Int. Conf. MysuruCon 2023, pp. 1–6, Dec. 2023, doi: 10.1109/MYSURUCON59703.2023.10396964.
T. T. H. Nguyen, A. Jatowt, M. Coustaty, and A. Doucet, “Survey of Post-OCR Processing Approaches,” ACM Comput. Surv., vol. 54, no. 6, pp. 1–37, Jul. 2021, doi: 10.1145/3453476.
Sanjay Kumar Gorai and Shekhar Pradhan, “Bridging the Gap: OCR Techniques for Noisy and Distorted Texts,” Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol., vol. 11, no. 1, pp. 695–703, Jan. 2025, doi: 10.32628/CSEIT2511111.
“R-Vogg-Blog: Fuzzy string matching.” Accessed: Apr. 20, 2025
“Character string fuzzy matching method and apparatus,” Oct. 12, 2016. Accessed: Apr. 15, 2025.
M. Vakili, M. Ghamsari, and M. Rezaei, “Performance Analysis and Comparison of Machine and Deep Learning Algorithms for IoT Data Classification,” Jan. 2020, Accessed: Nov. 20, 2024.
O. Caelen, “A Bayesian interpretation of the confusion matrix,” Ann. Math. Artif. Intell., vol. 81, no. 3–4, pp. 429–450, Dec. 2017, doi: 10.1007/S10472-017-9564-8/METRICS.
“Food package detection method,” Jul. 27, 2016. Accessed: Apr. 15, 2025.
Downloads
Published
Issue
Section
License
Authors retain copyright and full publishing rights to their articles. Upon acceptance, authors grant Indonesian Journal of Data and Science a non-exclusive license to publish the work and to identify itself as the original publisher.
Self-archiving. Authors may deposit the submitted version, accepted manuscript, and version of record in institutional or subject repositories, with citation to the published article and a link to the version of record on the journal website.
Commercial permissions. Uses intended for commercial advantage or monetary compensation are not permitted under CC BY-NC 4.0. For permissions, contact the editorial office at ijodas.journal@gmail.com.
Legacy notice. Some earlier PDFs may display “Copyright © [Journal Name]” or only a CC BY-NC logo without the full license text. To ensure clarity, the authors maintain copyright, and all articles are distributed under CC BY-NC 4.0. Where any discrepancy exists, this policy and the article landing-page license statement prevail.












